

▲头图由昆仑万维天工大模型生成▲
随着大模型技术迎来颠覆性突破,新兴AI应用大量涌现,不断重塑着人类、机器与智能的关系。
为此,昆仑万维集团重磅推出《天工一刻》系列产业观察栏目。在本栏目中,我们将对大模型产业热点、技术创新、应用案例进行深度解读,同时邀请学术专家、行业领袖分享优秀的大模型行业趋势、技术进展,以飨读者。

当前,大模型领域最火的研究方向之一,当属多模态大模型。
自大模型技术兴起以来,海量AI辅助创作的文案、图像、视频却如雨后春笋般涌现;其中最成熟的,正是图文多模态大模型。
自2023年初开始,微软KOSMOS-1、谷歌PaLM-E、OpenAI GPT-4/4V、Mate ImageBind、开源项目MiniGPT-4、开源项目LLaVA……还有Flamingo系列、CLIP系列、BLIP系列、DALL·E系列、Stable Diffusion系列等一大批技术创新涌现,产业风起云涌,好不热闹。
AI画画、AI证件照、AI解释“表情包”、AI发票识别……这些令人惊叹的新兴AI应用背后,都离不开多模态技术的“加持”。可以说,看懂了多模态大模型,才能真正了解大模型的未来。
2023年8月,昆仑万维推出国内第一款AI搜索引擎,成为中国AI搜索鼻祖。当前,基于自研“天工”系列基座大模型,昆仑万维已构建起AI大模型、AI搜索、AI音乐、AI Story、AI游戏等AI业务矩阵。
在天工AI智能助手APP中,用户也可以通过AI画画、AI识图等功能,体验到天工大模型强大的多模态AI功能。
本文将从以下方向介绍多模态技术:
1、什么是图文多模态大模型?
2、图文多模态大模型的三大研究方向
3、图文多模态大模型的主流技术方向
4、前沿创新与天工自研Mental Notes技术
早在2023年9月初,昆仑万维天工大模型团队就推出了自研多模态大模型Skywork-MM v1。
Skywork-MM由一个视觉编码器、一个可学习采样器模块和一个经LoRA调优后的大语言模型组成。
针对目前困扰多模态大模型领域的众多挑战,昆仑万维团队从特定SFT数据集训练、知识定义与诱导、模型结构、训练方式等领域进行创新,并推出自研Mental Notes技术,模拟人类认知过程,显著降低了多模态大模型“幻觉”问题,增强了中文的指令追随能力、中文相关场景的识别能力,降低了文化偏见对于多模态理解造成的限制。
同时,昆仑万维天工大模型团队还公开了名为《Empirical Study Towards Building An Effective Multi-Modal Large Language Model》的技术论文。

▲昆仑万维天工多模态大模型团队论文截图▲
01 当我们谈论多模态时,我们在谈论什么
模态(Modal)在计算机用语中,可以理解为计算机和人之间的单一独立感官输入与输出通道的分类——如文字、图像、声音。
与多模态相对应的是单模态,即单一交互种类。举例而言,ChatGPT就是一种典型的单模态产品,在2022年11月发布之初,它只能用文字与用户进行交流,而GPT-4V则能同时处理文字和图像信息。
对于人类来说,多模态是一种极其自然的交互方式。看一段带字幕的视频、欣赏一朵颜色娇艳的鲜花,我们的眼睛、耳朵、鼻子能同时接收到来自外界的信号,并由大脑统一调控处理。
但对于计算机而言,这种多模态交互却极其不自然。
在计算机领域,一直以来,各类模态的研究都在“单兵作战”。
做图像的专注做图像,做文本的做文本,偶尔有人想做个模态融合,却往往苦于技术局限,难以打破模态壁垒。
比如,上一轮席卷全球的人工智能热潮正是在图像领域(CV,计算机视觉Computer Vision)。
彼时,由于CNN(卷积神经网络)技术取得突破,带动了人脸识别、图像识别、视频检测等一大批图像领域的创新突破,准确率迅速超越人类,达到商用标准。
不幸的是,这项技术在文本理解上的效果相当一般。当时一个AI程序能够在人脸识别的精准度上达到99.99%,却在人类语言理解上不如一个幼儿园的小朋友。
而本轮人工智能热潮则发源于文本领域(NLP,自然语言理解Natural Language Processing)。
2018年,预训练Transformer模型横空出世,在文本领域掀起革命,一夜之间,以GPT为代表的大语言模型(LLM, Large Language Model)席卷全球,大模型火爆全网。
此时,有趣的事情发生了。
但当研究人员将Transformer结构试图用于图像领域,设计出ViT(Vision Transformer)结构时,竟在图像领域取得了极其惊人的良好效果。
ViT将图像划分为固定像素大小的正方形的单元作为token,通过分单元处理与线性映射,使得每个像素方块成为了基于单词设计的Transformer结构可接受的输入,一举打破了CV和NLP之间的壁垒。
2020年10月22日,《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》论文发布。自此,一扇新世界的大门打开了。
02 图文多模态技术三大研究方向
从流程来看,图文多模态大模型可以大致划分为输入、输出两个步骤;从技术上则可以分为:
专注输入的多模态理解模型Understanding Models
专注输出的多模态生成模型Generation Models
统一理解与生成的通用模型General-Purpose Models
其中,理解模型是当前学术与产业界的研究重点。
在理解模型领域,虽然基于Transformer理念设计的ViT模型面世之后,该研究方向取得了显著突破,但目前学术与产业界尚存争论,各类新兴技术路径依旧是百花齐放,如CLIP、LLaVA、MiniGPT-4等。
而在生成模型领域,自从Diffusion Model(扩散模型)横空出世,霸榜全球后,生成侧模型几乎已被Diffusion“一统天下”。目前大量AI作画、AI写真等都是Diffusion系列的产品,只是在大方向上各细分路径有所不同。
此外,统一理解与生成侧的通用基础模型也是当前多模态领域的研究热点,基于BLIP系列技术的多模态创新在多项应用上都取得了良好效果。
03 主流技术方向
当前,在最为广泛应用的视觉+文本多模态大模型领域,研究效果最好的主流方案之一是基于预训练的图像编码器与大语言模型,以图文特征对齐模块进行跨模态的信息链接,从而让擅长NLP技术的语言模型能够理解图像特征,并进行更深层的问答推理。
这样可以利用已有的大量单模态训练数据训练得到的单模态模型,减少对于高质量图文对数据的依赖,并通过特征对齐、指令微调等方式打通两个模态的表征。
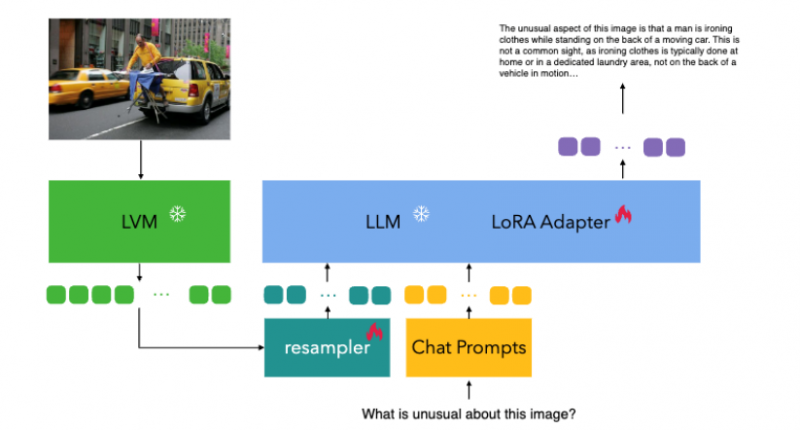
▲昆仑万维多模态大模型Skywork-MM架构▲
Skywork-MM将视觉模型/图像编码器和大语言模型完全冻结,保持视觉模型在前置CLIP训练中学习到的视觉特征不损失,大语言模型的语言能力不损失。
同时,为了更好的关联视觉特征和语言特征,模型整体包含了一个可学习的视觉特征采样器和语言模型的LoRA适配器。
Skywork-MM模型训练分为两个阶段:
第一阶段,使用双语的大规模图像-文本配对数据进行图像概念和语言概念的关联学习;
第二阶段,使用多模态微调数据进行指令微调。
04 学术前沿
尽管在跨模态能力泛化上效果优秀,但当前的多模态大模型——尤其是中文多模态领域——依旧存在着不少挑战:
1、幻觉问题
大模型的幻觉问题指的是模型生成的文本或回复与原文产生信息冲突(Faithfulness)或者不符合基础事实(Factualness)。这是一个普遍存在于众多大模型产品中的问题,尤其是在多模态技术领域。
昆仑万维天工团队观察到,当前的多模态大模型不仅普遍存在“幻觉”问题,而且用户在向大模型询问输入图像中的不可见对象或事实冲突的相关问题时,现有大模型更倾向于给出“是”或产生“幻觉”。
2、中文/英语-双语大模型的挑战
数据方面,多模态训练数据本就极其稀缺,收集图像数据的成本通常比收集文本数据的成本高得多。因此,视觉数据的规模通常比文本语料库的规模小得多。并且,在图像与视觉领域,数据的颗粒度和语义丰富度都不尽相同,大到整个图像、区域(框标准),小到掩码(像素标注)。其中,能够进行高质量图像-文本配对的中文数据更是少之又少。
而在模型方面,昆仑万维天工团队同样观察到,基于Chinese-LLaVA或ImageBind-LLM等海外双语多模态大模型构建中文多模态大模型效果很差,其不仅在回答汉语问题时会存在文化偏见,在不少大模型中,即使用中文指令数据进行微调,也无法识别具有典型中文特征的项目。
针对多模态大模型所面临的众多挑战,昆仑万维团队从特定SFT数据集训练、知识定义与诱导、模型结构、训练方式等领域进行创新,并推出自研Mental Notes技术,模拟人类认知过程,显著降低了Skywork-MM的“幻觉”问题,增强了中文的指令追随能力、中文相关场景的识别能力,降低了文化偏见对于多模态理解造成的限制。
昆仑万维天工团队自研的Mental Notes技术通过训练大模型在回答问题之前提供图像的详细描述,这一过程与人类提前准备引导笔记以回答问题时的认知过程类似。通过引入Mental Notes技术,系统显著提高了多模态大模型在图像-文本任务上的效果,在众多相关任务中表现优秀。
此外,与其他多模态大模型相比,Skywork-MM更是在数据使用效率上效果惊人,其图像-文本对训练数据少于50M,其多模态性能显著超过其他同类100M大模型。
2023年,Skywork-MM在腾讯优图实验室联合厦门大学开展的基于MME的全球多模态大语言模型测评中取得综合得分排名第一、感知榜单排名第一、认知榜单排名第二。
当前,昆仑万维业务覆盖AGI与AIGC、信息分发、社交娱乐及游戏等多个领域,全球平均月活跃用户近4亿,覆盖一百多个国家和地区,是全球领先的人工智能科技企业,也是国内模型技术与工程能力最强、布局最全面的人工智能企业之一。未来,昆仑万维将加速提升多模态能力,将研究、研发与产品相结合,不断升级用户体验支撑旗下AI产品发展。












 营业执照公示信息
营业执照公示信息